机器人空间感知的场景表达形式的综述论文阅读笔记
相关连接
空间感知基础
-
构建场景就是用原始的传感器数据增量式的构建机器人周边的环境,同时估计机器人自身位置。并且机器人可以在这个地图上做自主导航,并且和周围环境进行交互。作者将这类地图分为三个抽象的层次:
- metric:场景的几何信息
- semantic:分辨物体的类别或者整个场景的语义信息
- topological:场景和物体之间,以及物体之间的相互关系

-
如果要设计一个机器人空间感知系统,或者是一个空间的表示形式时,作者提供了一些需要考虑的关键要素:
- Metric accuracy(几何精度):除了几何精度以外,还需要保持地图和真实环境的一致性,例如空间中的每个位置,都只有一个地图中的点与其对应。
- Semantic richness(语义丰富度):空间中物体的实例分类,甚至是场景的语义理解,例如室内场景,要把不同的房间区分开。
- Scalability(可扩展性):场景的表示形式要能够适应不同大小的场景,室内小场景,室外复杂环境,甚至整个城市的表达。因此当新数据进来时,要能实现实时的推理和更新,并且只动态的更新新观测到的部分。需要做到内存和计算资源的管理以及精度和丰富度的平衡。
- Efficiency(效率):与上一点类似,要能实时运行。
- Robustness(鲁棒性):不仅能处理传感器的噪声,还要能处理环境的变化,甚至部分系统故障时也能正常运行。
- Long-term persistence(长期持久性):在机器人的长期运行中,可以持续的更新和维护地图。
- Multi-modal integration(多模态融合):能接纳多传感器的数据,例如相机,LiDAR,声呐,触觉传感器等。
- Interpretablity and usability(可解释性和可用性):这个场景既能让机器人理解,又能让人类理解。
场景表示形式
- 主要分为三个大类:metric,metric-semantic和metric-semantic-topological。以下是一个概览:
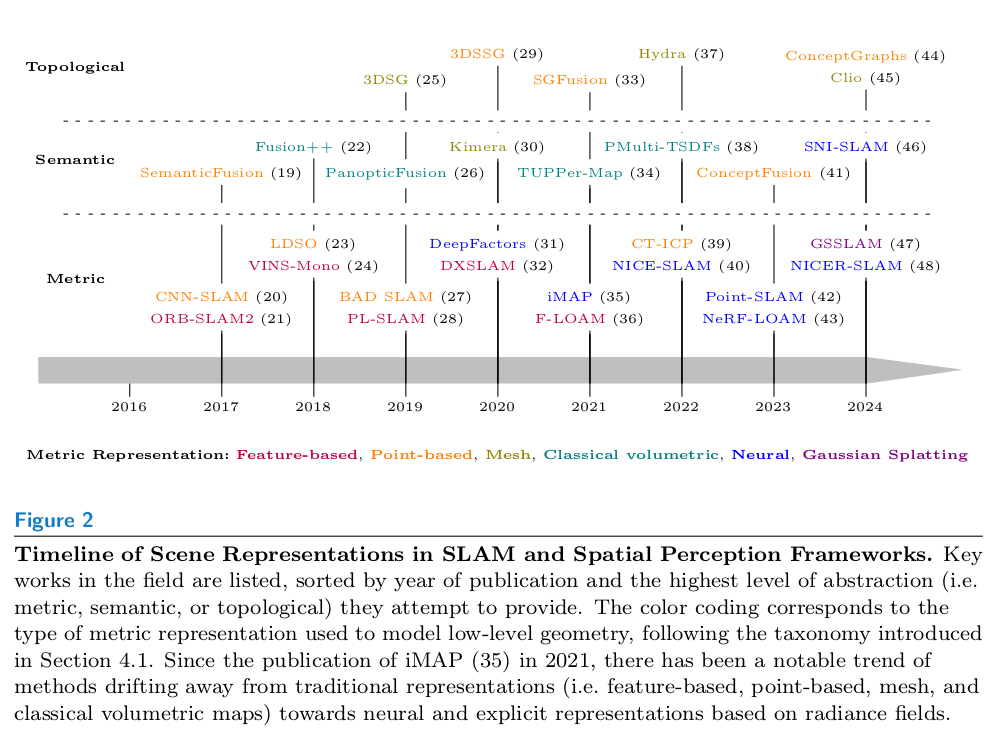
Metric Representations(只包括几何信息)
- 这一类就是纯做SLAM了。
Feature-based representations(基于稀疏特征的表示形式)
- 传感器捕捉场景中的特征点或者Landmark,然后用这些特征点来构建地图。视觉SLAM中主要是用这种方法,构建稀疏特征点的地图,例如ORB-SLAM。也有一些利用深度学习的方法提取特征,或者提取空间中的线面特征的VSLAM方法,在LiDAR-based的SLAM中,LOAM及其变种也都是特征点法。
Dense (and semi-dense) point-based representations(密集点云表示形式)
- 基于RGBD和LiDAR的SLAM主要生成的是稠密点云,其主要目标是做状态估计,根据输入数据做匹配,计算当前位置和姿态。也有一些用神经网络代替传统SLAM的后端,直接估计单目的深度实现稠密点云的构建,例如DVSO和D3VO。这类方法对于单目和的尺度估计和无纹理区域的深度估计有比较大的提升。
Surface mesh representations(表面网格表示形式)
- 实时生成mesh,主要是从一些基础的数据结构中转换而来的,例如基于LiDAR的ImMesh,很少有实时生成mesh同时也动态的优化mesh的方法,例如基于Lidar生成mesh的puma以及SLAMesh

Classical volumetric representations(传统体积表示形式)
- 这种体积表示的方法,主要目标是既表示3D的几何信息,又把free space表示出来,这种可能会更适合机器人做自主导航和规划。比较常用的方法是
- occupancy maps(占据栅格):明确的表示free space和occupied space。
- Signed Distance Fields(SDF):每个点保存其到最近表面的正交距离(有正有负)。
- 与占据栅格相关的方法中,比较经典的方法有OctoMap,其将空间中的点按照不同的分辨率保存,加快了对空间栅格的访问。其他的对OctoMap的访问做加速的框架有UFOMap以及利用GPU+ray tracing的OctoMap-RT,比OctoMap快三十几倍。

-
由于栅格的离散特性,使得这种建模方法会有不准确的地方,因此后续提出了NDT(Normal Distributions Transform)的方案。NDT将每个栅格建模成一个局部的高斯分布,将环境可以实现分段的连续表示。因此在比较大的体素尺寸时也可以达到比较好的建模精度,并且进一步促进了类似的Hilbert maps和Gaussian Mixture Models(GMMs)的发展。
-
另一种基于TSDF的方法由于可以实现亚体素的分辨率以及实现传感器的去噪,在SLAM中应用也比较广泛。比较有名的KinectFusion。为了更好的支持轨迹规划,很多框架目标是在动态增长的地图上实时构建完整的SDF,因为这类方法允许从空间中任何一个点有效的查询到障碍物的距离和梯度。
- 例如,有遵循voxel-hashing的Volblox,它整合传感器的投影后的TSDF逐步构建SDF map。

- Voxfield引入了一个不需要投影的TSDF公式来实现更高精度的SDF并实现了高效的计算。

- 基于GPU做加速的nvblox

- 以及基于多分辨率构建SDF以节省内存的方法:Adaptive-resolution octree-based volumetric SLAM和Efficient Octree-Based Volumetric SLAM Supporting Signed-Distance and Occupancy Mapping
Neural implicit representations(神经隐式表示)
- 基于深度学习的模型来做场景纹理和几何信息的隐式表达。
- 早期的工作主要是用深度autoencoders来自动发觉高维图像的高级、紧凑表示。CodeSLAM在VSLAM中,将观察到的图片编码成紧凑且可优化的表示,且这种编码形式包含了稠密场景的基本信息。DeepFactors将这种隐式表达整合到一个全特征,基于关键帧的SLAM框架中。

- 最近3年,NeRF方法兴起,也带起了一批基于NeRF的SLAM方法。基于自监督学习的方法,隐式的学习并建模三维场景的结构和纹理并实现新视角的合成,这个方法在RGB-D SLAM领域被迅速的采用。iMap使用MLP将3D坐标映射到颜色和体积密度,而无需考虑观察方向等问题。尽管这种方法可以实现紧凑且连续的场景建模,但他让3D表面过于平滑,并且有灾难性遗忘、推理速度过慢等问题。考虑到以上问题,MeSLAM和NISB-Map采用了多个MLP网络,分别代表场景中的不同部分。
- NICE-SLAM采用了基于栅格的表示方法,其引入了固定大小,coarse-to-fine的特征栅格,使其在大型的室内场景中也可以重建出更好的细节。

- Vox-Fusion采用八叉树来存储grid embeddings,使其在场景扩展时可以动态的分配新的体素。

- Co-SLAM将one-blob编码提供的平滑度与多分辨率的hash-based的特征栅格的快速收敛与局部细节优势结合起来,进一步提高了Vox-Fusion的效果。

- ESLAM用多尺度、坐标轴对齐的特征平面代替特征栅格,将场景增长的规模从三次方缩小到二次方。

- 除了基于栅格的表达的方法外,基于混合神经点的表达方法也有一些,例如Point-SLAM和Loopy-SLAM。这种点表示的方法,和栅格方法不同,无需预先定义栅格的分辨率,因此对于内存的使用也更有效,并且可以捕捉更多的细节。整体看下来,基于点的方法重建的效果更佳。


- 以上都是RGBD相机的稠密重建,对于RGB相机的重建也有一些工作。iMODE用ORB-SLAM2实时计算相机的pose,并优化MLP用于神经场表示。类似的工作还有Orbeez-SLAM和NeRF-SLAM都是先用VSLAM获得相机的位姿,然后用Instant-NGP做实时重建。NICER-SLAM引入了一个端到端的网络,可以同时优化相机pose和基于SDF和颜色的分层神经隐式映射场。

- 在基于LiDAR的重建中,NeRF-LOAM在构建神经表示的同时,优化LiDAR的位姿,并且采用八叉树的结构中采用动态的体素嵌入,可以有效的捕捉局部几何信息。LONER正相反,它使用ICP估计LiDAR的位姿,并用具有分层特征网格编码的MLP来表示场景。PIN-SLAM利用基于点的隐式神经图表示与“无需对应点”的“点到隐式模型”的配准方法结合,实现姿态估计,并且允许在全局姿态调整期间连续变形。


Explicit radiance field representations(显式辐射场表示)


- 单目相机的SLAM重建方法有Gaussian Splatting SLAM
- 以及针对LiDAR-Inertial-Vision融合的LIV-GaussMap

- 以上这些方法都很依赖初始化,以及对未观察到的区域的重建效果较差,并且3DGS为了实现场景重建的精度,使用了大量的高斯基元,因此对内存的占用也比较大。
Metric-Semantic Representations(同时包含几何信息和语义信息)
- 与上面介绍的方法不同,这类方法给场景的几何信息增加了语义标签(例如:物体的种类),这类方法主要受益于object-detection,classification和scene understanding的深度学习方法的快速发展。
- 这类场景表示主要分为4类:object-centric,semantically-labeled, panptic和open-set representations.
Object-centric representations(物体为中心的表示)
- 这类方法主要对目标物体有区分和重建,其他部分的语义信息则会直接忽视。早期的方法是有一个3D模型库,并且要求物体的几何形状和库里的模型保持一致。受益于CNN的发展,对于物体的类别、姿态和尺寸都可以很好的估计出来,因此在基于lanemark的SLAM方法中用的很多。例如用dual quadric fromulation(对偶二次曲面)方法将物体建模成3D椭圆的QuadricSLAM,以及用物体的BBOX计算残差的CubeSLAM。

- 目前基于RGB-D的场景稠密重建方法发展速度更快。Fusion++用Mask R-CNN预测image中物体的mask,并逐步构建3D物体模型,并把它作为pose graph中可优化的landmark。与其类似,Voxblox++把Mask R-CNN和增量几何场景分割方法结合起来,实现了一个有物体语义实例的建图方法,可以生成新观测到的和已经有的物体的位姿和形状。
- 后续的《Volumetric Instance-Level Semantic Mapping Via Multi-View 2D-to-3D Label Diffusion》使用Mask R-CNN预测提取3D物体的instance,这些实例使用标签扩展方案集成到全局的稠密地图后能被进一步的细化,并且将这类方法更好的适用于Vision-LiDAR的传感器组合。
- 以上方法主要使用点云和TSDF来表示场景,vMAP提供了一个新思路,为每个物体,设置一个专用的MLP表示,最终实现object-level的稠密建图。这种方法有助于构建水密(watertight)和完整的物体模型,即使实时的RGB-D数据有遮挡。类似的,RO-MAP从单目相机的RGB输入中,结合NeRF模型实现了轻量级的object-centric的SLAM方法。他为每个物体单独训练一个NeRF模型,实现了在没有深度先验信息的情况下,实时重建物体。

Semantically-labeled representations(语义标签的表示)
- 这类方法是给构建的场景中的每个点、surfel或者voxel体素赋予一个语义标签或者分布概率标签。比较有代表性的工作有基于RGB-D的SemanticFusion,他首次用CNN推断每个像素的类别的概率分布,然后用贝叶斯更新方法聚合到surfel的地图上。类似的Kimera同时将逐帧的语义分割结果、IMU测量和可选择的深度估计集成到一个mesh表示中,实现了实时的语义SLAM。SuMa++和SA-LOAM则是基于LiDAR的语义分割SLAM方法。


- 最近做的比较多的则是基于RGB-D传感器,以神经场的形式表示场景。SNI-SLAM使用神经隐式表示,分层语义编码实现多层次的场景理解,并用cross-attention机制协同整合外观,几何和语义特征。
- SGS-SLAM和SemGauss-SLAM
正相反,都是基于3DGS的语义稠密SLAM方法。SGS-SLAM是将语义信息作为RGB的额外一个通道,并在关键帧处优化语义分割点。SemGauss-SLAM则是给3DGS扩展了语义编码,是其能获得更高精度的3D语义分割。


Panoptic representations(全景式表示)
- 上述方法无法分割出同一类别的实例信息,为了解决这个问题,所谓的Panoptic representations(全景表示)就是结合背景区域的标签,同时单独分割和识别任意前景对象。《Real-time Progressive 3D Semantic Segmentation for Indoor Scenes》使用纯语义分割策略,然后在场景中聚类实现实例分割。这种聚类的方法纯基于几何信息,因此分割出来的实例肯定不准。最近基于RGB-D的建图方法,将深度学习的全景分割和传统的体积表示形式结合了起来。Panoptic Multi-TSDFs实现了多分辨率的体素建图,他将整个环境建模型一组submap,每个代表一个实例物体或者一块背景,并且每块都有自己的分辨率,这样就可以做到动态环境的更新。

- 除了传统的体积表示,PanoRecon还有EPRecon还提出了一种可以实时增量式的进行3D几何重建以及3D全景分割的框架。同时还有一些基于神经辐射场的方法,将背景和前景解耦,但是耗时比较长,因此只能离线运行。

Open-set representations(开放集表示)
- 大多数构建语义地图的方法,都局限于目前的闭集,只有预训练中见过的类别才能被识别到。因此为了应对这个问题,最近出现了由基础模型驱动的开放集表示的方法。这些新颖的框架能够将开放集特征融合到3D地图中,从而允许以后灵活的查询和解释。这一新兴领域最具代表性的例子之一是ConceptFusion,它证明了像素对齐的开放集特征可以通过传统的SLAM和多视图融合方法融合到3D地图中,从而实现有效的zero-shot空间推理。

Metric-Semantic-Topological Representations(同时包含几何信息、语义信息和拓扑信息)
- 对于机器人导航来说,如果要理解并执行人类的指令,比如:“去厨房把我的咖啡杯拿来”,需要构建一个了解实例之间的关系并在不同层级构建关联的模型。目前已经有一些工作构建“3D Scene Graphs”来描述空间更丰富的信息,比如几何、位置、语义和拓扑关系。这种关系可以是“flat扁平”的,如果只关注单一层面,例如只是物体层;也可以是“hierarchical多层”的,比如从大到小的地点层面,建筑层面,房间层面,物体层面等。
- 3DSSG(离线运行)和SceneGraphFusion(增量处理)用学习的方法,从不知道类别的,聚类后的点云中,推断物体之间的空间位置关系;

- Hydra实现了可以实时运行的多层3D sence graph。它构建机器人周围的Euclidean Signed Distance Field(ESDF)并增量式的将其转成语义3D mesh,并且可以提取出场地和房间。

- 最近的concept-graphs和Clio也是类似的构建单层和多层的语义拓扑关系图。

Dynamic Scene Representations(动态场景表示)
- 历史上,绝大多数SLAM和空间感知框架都假设世界是静态的。然而,现实世界的环境通常是动态的,具有移动的人和物体,不断变化的条件(例如照明,天气)和不断变化的物体。
Short-term dynamic(短期动态)
- 过去几年里,很多工作都在解决直接能观察到的运动。基于特征的SLAM方法主要是把动态的实体过滤掉,例如DS-SLAM,DynaSLAM和dynaVINS,或者是假设物体有比较好的运动,然后把这个问题直接集成到SLAM中。



- MaskFusion, Mid-Fusion和EM-Fusion利用物体检测跟踪移动的物体,并对其做栅格的稠密重建。

Long-term dynamic(长期动态)
- 以上方法都无法识别长期的变化,例如只有经过很长一段时间后,重新回到当前位置,才能发现的变化。假设已知机器人位姿,POCD将object-level信息和全景TSDF地图的一致性进行对比,实现object的位置更新。最近的POV-SLAM引入了一种对象感知、因子图SLAM公式,能够跟踪和重建半静态对象级变化。
Short- and long-term dynamic(短期和长期动态)
- 还有一些结合了短期动态和长期动态的方法,Changign-SLAM构建了稀疏特征点地图,采用贝叶斯滤波方法检测短期动态物体,数据关联方法检测长期变化,并把检测到的动态点从SLAM中移除。Khronos实现了第一个能实时生成spatio-temporal(时空)度量的语义地图框架。同时能优化机器人位姿和稠密语义地图。

Deformable environments(变形环境)
- 另一个特别具有挑战性且未被充分探索的问题是映射可变形环境,或包含非刚性可变形对象的环境。例如DynamicFusion就是对运动的人脸实现稠密重建。
Discussion
A Universal Scene Representation(通用场景表示)
- 虽然人们普遍认为先进的空间感知将是下一代机器人和自主系统的关键推动因素,但目前还不清楚底层的场景表示应该是什么。挑战在于确定一种最优的场景表示,能够在准确性、效率、可扩展性和可解释性等几个相互竞争的属性之间取得平衡。这些因素对于满足旨在在现实世界中智能运行的自主系统的多样化需求至关重要。机器人预期执行的任务范围广泛,以及需要考虑的潜在部署环境的多样性,导致了使用的平台和传感器种类越来越多。与此同时,合适的场景表示的选择与手头任务的具体要求以及可用的传感器紧密相关。每个任务可能对地图的细节程度、语义理解或时间持久性有不同的要求,而机载传感器的能力和局限性决定了可以捕获的信息类型和质量。**因此,期望单一通用的表示方法能够满足所有可能的使用场景是不切实际的。**尽管如今在系统中对 3D 几何建模的方式存在明显差异,但似乎仍存在将几何抽象为更高层次概念的明确需求,从而实现基于语义的推理。因此,开发能够整合不同抽象层次(即从低层次的几何细节到对象、实体和场所)的任务相关信息,并以某种标准化方式查询的通用灵活框架具有巨大潜力。如何有效地构建这些框架以适应各种度量表示、语义抽象和时间尺度,仍然是一个未解决的问题。
Real-time and Scalability Considerations for Practical Deployment(实时性和可扩展性考量,以实现实际部署)
- **当前空间感知框架的主要局限之一,尤其是那些旨在超越纯几何 SLAM 的框架,是难以实现实时处理。**这通常是由所选地图数据结构的计算复杂性以及用于更新其中所含信息的方法所导致的。此外,许多此类系统,例如基于新型神经表示的系统,需要强大的 GPU 硬件,这阻碍了它们在资源受限平台上的部署。未来的一个关键挑战是开发出更快、更高效的算法,能够在计算能力有限的嵌入式系统上运行,从而更广泛地应用先进的感知框架。
- 另一个尚未解决的问题是,需要确保空间感知系统能够扩展到大型和复杂的环境中,同时保持准确性。对能够根据环境复杂性自动调整其细节水平的度量表示的研究,例如多分辨率体积地图或基于 3DGS 的表示,似乎是朝着这个方向迈出的有希望的一步。此外,在操作时,在相对较大的环境中,机器人可能并非始终需要即时获取所有详细的度量信息。这一观察结果表明,有可能开发出先进的模型,根据机器人当前的位置和任务需求,从长期记忆中选择性地将相关数据提取到短期记忆中。这种概念为进一步的研究开辟了一个有趣的领域,因为它有望减轻机器人的认知负荷并优化处理效率。
View-based vs. Map-based Inference of High-Level Concepts(基于视图与基于地图的高级概念推理)
- 是从单一视图中提取语义,然后用于建图;还是先建图,然后从map中提取语义
- View-based:目前将语义融入空间感知系统的主要方法是通过学习到的感知模型处理输入的传感器数据,将其输出视为虚拟传感器测量值,从而能够逐步融合到机器人的世界模型中。采用这种“基于视图”的方法,而非从地图本身推断出高级概念的主要原因在于原始传感器数据(例如图像)的保真度更高,相较于压缩且可能有噪声的场景表示,同时处理原始传感器数据的神经网络比基于地图的神经网络更为成熟,并且得益于更广泛的训练数据可用性,通常具有更好的泛化能力。基于视图的方法的另一个关键优势在于其能够在在线建图过程中即时访问高级概念,从而避免了基于地图的方法所固有的部分或完全的三维度量重建场景的需求。
- Map-based:尽管由于主要为离线目的而设计,基于地图的方法不在本文讨论范围内,但值得一提的是,基于地图的方法在某些情况下仍具有优势,例如在需要精确的三维重建或对场景进行详细分析时。在计算机视觉文献中,关于这一主题也有大量的研究工作。然而,迄今为止,很少有人致力于从不断更新的地图或机器人与其环境及人类交互的历史中推导出语义。这一研究空白凸显了一个机会,即开发更复杂的系统,使其能够随着时间的推移,在观察和与周围环境互动的过程中动态更新对场景的语义理解。整合时间、上下文和交互数据能够提供更深入的见解,从而增强机器人的整体空间感知能力。
- 在此背景下,探索结合基于视图和基于地图的语义推理的混合方法似乎是进一步研究的一个有趣方向。这样的系统将利用基于视图方法的实时适应性和响应性,以及基于地图方法提供的更好的上下文推理能力。这种结合有可能显著增强机器人语义感知的稳健性和可靠性,使其能够在各种环境中更有效地运行。
Towards Long-term Autonomy
- 目前最先进的空间感知框架主要是在相对准确的姿态估计以及空间和/或时间有限的部署假设下进行演示的。然而,这些系统需要在长时间内运行并构建持久的场景表示,这带来了若干挑战。
- 首先,空间感知系统的闭环性质需要高效的全局优化方法。当前的闭环检测和全局捆绑调整算法通常占用大量计算资源,尤其是在实时应用中,更新整个3D模型的复杂性往往变得难以承受。虽然已经提出了基于子地图的方法来缓解这一问题,但优化不断增长的地图的复杂性仍然是一个未解决的问题。
- 长期自主性固有的另一个问题是环境通常会随时间发生变化。因此,探索能够有效检测并适应这些变化的表示方法是至关重要的。特别是,在这种情况下,一个重要的新挑战是需要明确考虑并积极管理由不断变化的世界引入的不确定性。
- 最后,长期运行还要求机器人具备持续学习和适应的能力。这些系统需要在开放集条件下运行,因为它们不可避免地会通过持续观察遇到新的物体和场景。然而,迄今为止,大多数用于机器人感知的神经网络都是在封闭世界设置下训练的,具有固定数量的语义类别。尽管最近已经开始出现利用基础模型的开放集方法,但未来的一个重要挑战是在终身学习框架中利用深度网络的力量,使其能够推断新的语义概念并提高对先前未见环境的适应性。
机器人空间感知的场景表达形式的综述论文阅读笔记
https://fansaorz.github.io/2025/02/07/用于机器人空间感知的场景表达形式的综述论文阅读笔记/