ViT阅读笔记(Transformer在计算机视觉领域中的应用)
相关文档
Introduction
- 在自然语言处理领域,目前比较主流的方式是在一个比较大规模的数据集上做预训练,然后后再在一些特定领域里的小任务里去做fine-tuning。
- 在计算机视觉领域,目前主流的做法是使用卷积神经网络(CNN)来做特征提取,然后再用全连接层来做分类,例如AlexNet, ResNet等。目前已经有一些工作尝试将Transformer和CNN结合,主要用于解决视觉中Token过长的问题。例如Non-local neural networks就是把ResNet的中间特征图用在Transformer的输入上,Image经过ResNet提取特征后,维度降低至14x14,然后这个特征作为Transfomer的输入,而不是原始的224x224的图片。
- 本文的作者的想法是直接使用原始的Transformer框架来处理图像,尽可能少的改动模型。
- 因此本文的主要做法为:将每个图片拆解为一组16x16大小的patch,每个patch作为一个token(类似于NLP中的一个单词),然后对每个patch做Embededding,最后将这些patch的Embedding作为Transformer的输入。

- 最后,作者提到ViT和CNN-based方法的效果对比。在中小型数据集上,如果不加比较强的约束,ViT和同等大小的ResNet结构相比,是要差一点的。
- 然而这一点是可以预期的,因为卷积神经网络有一些先验知识在里面,例如locality,即相邻的像素点相关性比较高;以及translation equivariance,即图像的平移不变性,先做平移还是先做卷积,结果是一样的。
- ViT没有这些先验知识,这些信息需要自己从数据中学习,因此作者在实验中使用了更大的数据集,效果就比ResNet好了。
Method
Vision Transformer (ViT)
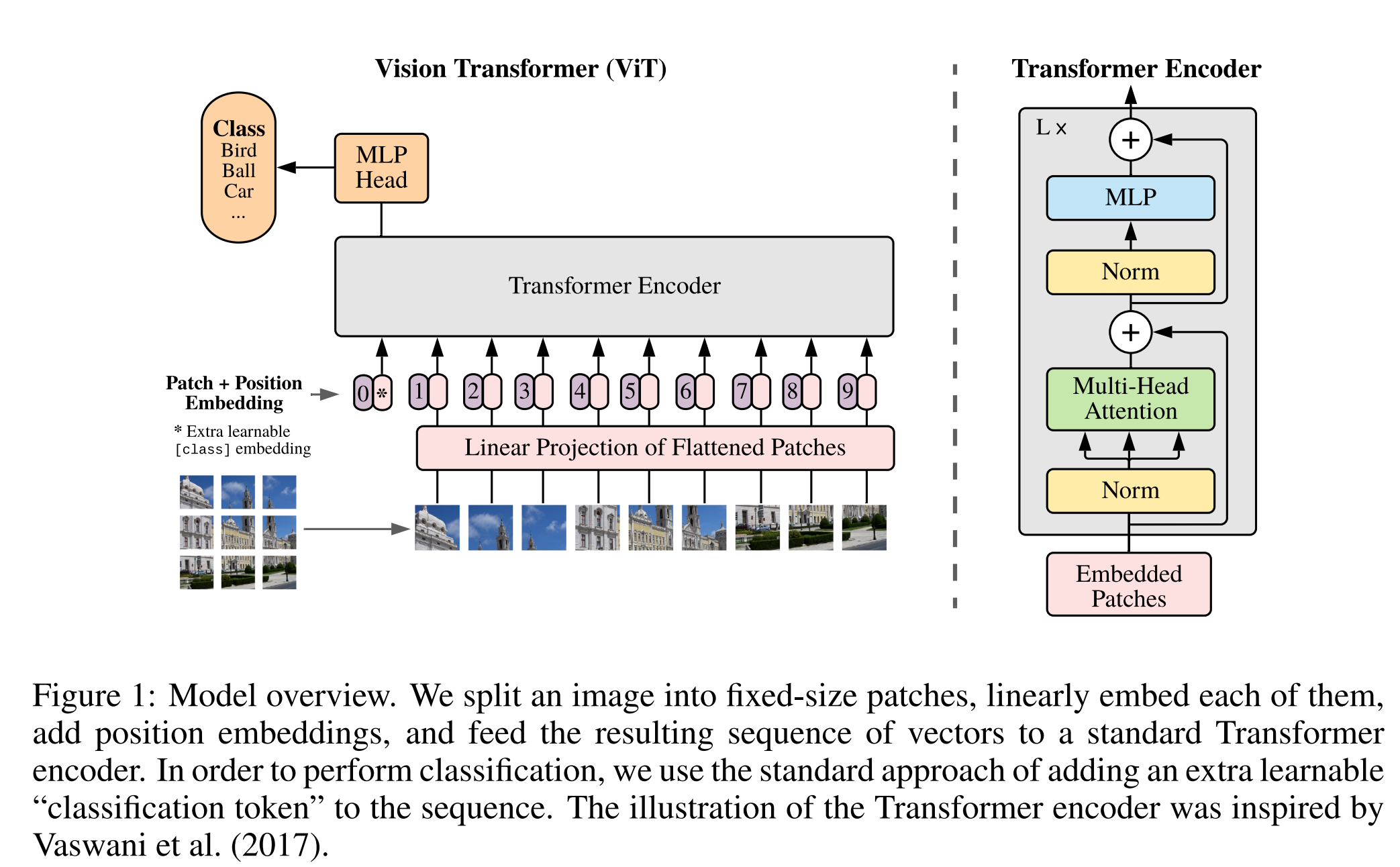
- 举例:
- 图像处理步骤:
- 输入一个224x224x3的图片,将其拆解为16x16x3=768维度的patch,总共14x14=196个patch。
- 设置一个线性投射层,对每个patch做embedding。这里是一个全连接层,输入维度为768,输出维度也为768。
- 至此,我们得到了196个Patch,每个patch维度为768,因此对于图像的输入维度为196x768。除此之外,还有一个位置为0的class token,它的维度也是768,此时的维度为197x768。
- 接下来,还需要加上位置编码的token。位置编码的实现方式为:设置一个表,大小为197x768,每一行代表一个位置编码,每一行的维度为768
- 最终,位置编码和patch embedding加起来(是sum而不是concat),这样维度就不会变化,还是197x768。
- Transformer Encoder步骤:
- 输入维度为197x768,在Multi-head Attention中,假设用了12个head,那么每个head的维度为768/12=64,此时每一个head的KQV的维度为197x64,同时有12个head。最终把12个head的结果concat起来,维度不变197x768。
- 图像处理步骤:
Fine-Tuning and Higher Resolution
- 这里作者介绍了如何在在fine-tuning阶段使用更大的图像尺寸。
- 当使用更大的图像尺寸,且保持patch大小不变的情况下,输入的token数量会更多,此时预训练得到的位置编码信息就会失效。例如预训练时是9宫格的位置编码,fine-tuning时变成了16宫格,就对不上了。此时可以对预训练的位置编码做插值(Pytorch的官方API就可以),但不能插值太大,不然也会有掉点。
Experiment
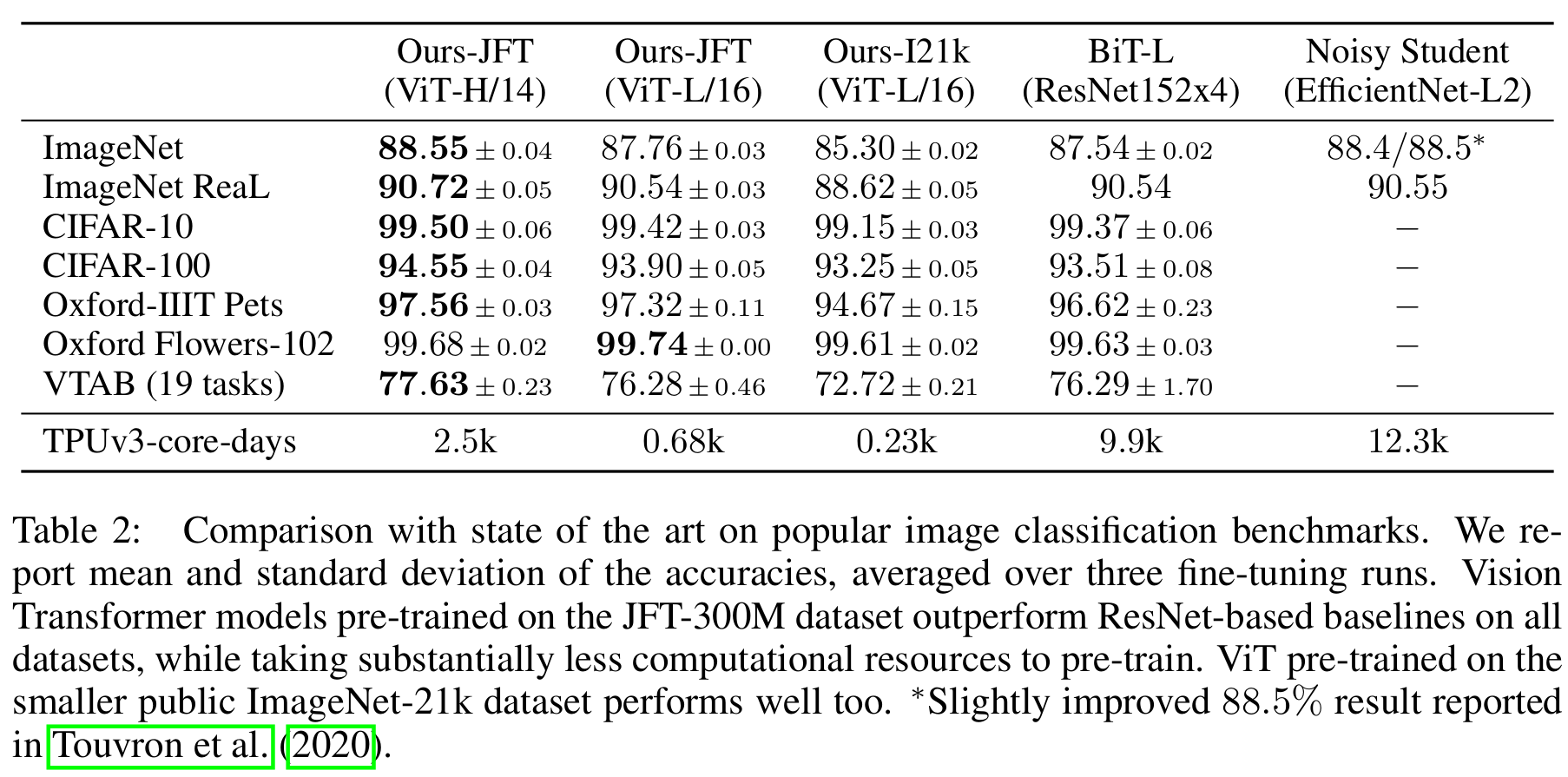
- 以下是关于模型在各个数据集上的表现,就不展开介绍了
补充信息
为什么需要一个class token
- 传统的ResNet的方式,是在最后一个ResNet网络的输出feature中,做一个GAP(Globally Average Pooling, 全局平均池化),然后接一个全连接层来做分类。而ViT的做法是加一个全局的class token,最后只针对这一个token的输出做分类。
- 作者这里也做了实验,发现这两种方法都可以,而使用class token的方法,主要是为了保持Transformer的一致性,因为Transformer的输入和输出都是token。
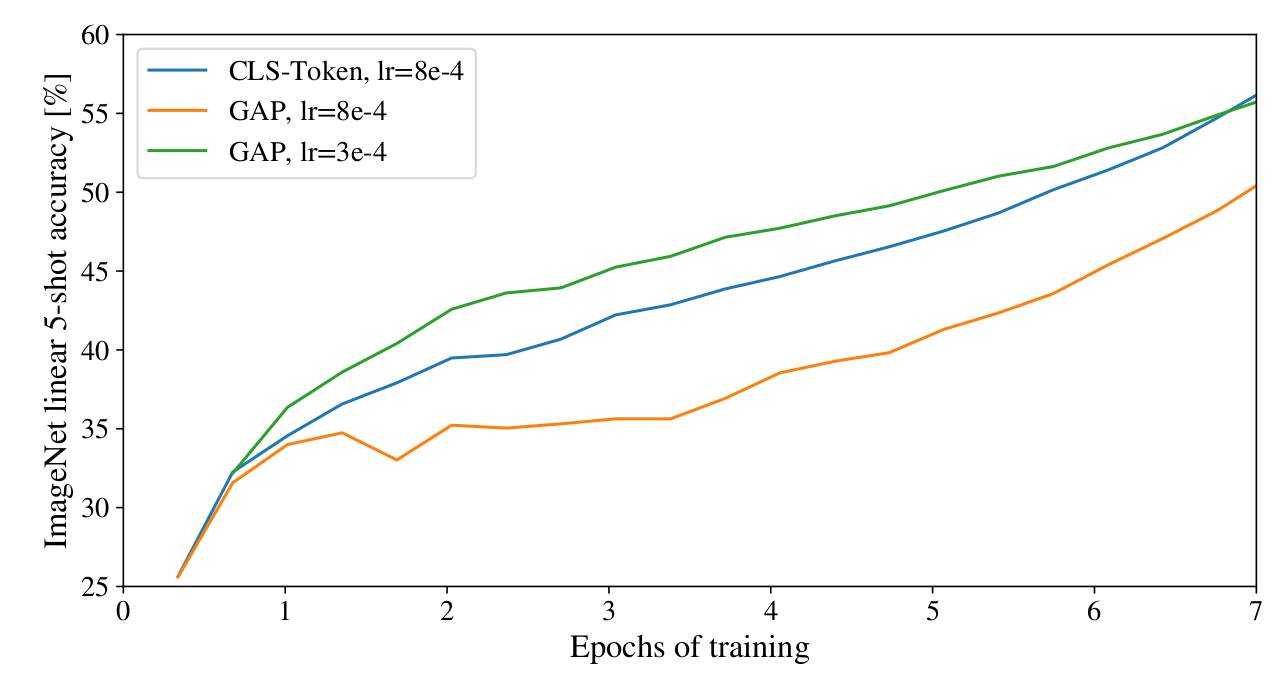
- 但是这两种方法的学习率是不一样的,还是需要对不同的方法调参。
位置编码
- 作者比较了不用的位置编码方法:
- 1-D:文中使用的位置编码,即1,2,3,4,5…
- 2-D:行列分开,即11,12,13…21,22,23…
- 相对位置编码:图像之间的相对位置关系
- 比较下来,影响不大

ViT阅读笔记(Transformer在计算机视觉领域中的应用)
https://fansaorz.github.io/2025/01/12/ViT阅读笔记/