MASt3R阅读笔记(DUSt3R的改进模型)

相关文档
- 项目链接:https://europe.naverlabs.com/blog/mast3r-matching-and-stereo-3d-reconstruction/
- 代码链接:https://github.com/naver/mast3r
- 论文链接:https://arxiv.org/abs/2406.09756
Introduction
- 相对于DUSt3R,MASt3R主要改进为添加了一个额外的head,输出两张图片匹配上的一组特征点。
- 作者认为,原始的基于稀疏特征点—+描述子的方法,由于只考虑了局部信息来提取描述子,而丢失了全局几何信息,因此在一些局部有重复纹理的区域以及低纹理的区域会匹配出错。
- SuperGlue也考虑到了这一点,因此在配对的过程中加入了全局优化的策略,但如果关键点和描述子都是用局部信息编码的,那么在配对时才考虑全局信息就有点晚了。
- 另外一个方向就是不用特征点,直接一次用整张图像做稠密匹配。**(主要是因为Transformer的出现,引入了attention机制)**比较有代表性的工作是LoFTR
- 尽管有一些方法在这些方向上做出了改进,但它们在Map-free的定位benchmark上的精度也并不高。作者认为是因为他们都把特征匹配作为2D-2D的问题来处理。然而特征匹配实际上描述的是一个3D特征点的匹配问题:“有关联的像素实际上是观察到相同3D点的像素”。
- 尽管DUSt3R可以用于匹配,但精度没那么高,因此作者加入了第二个head,用于回归局部稠密的局部特征图,并使用InfoNCE损失来训练,作者称整个框架为MASt3R(Matching And Stereo 3D Reconstruction)。作者在不同的尺度下使用coarse-to-fine的策略来得到像素级的匹配,并提出了一种更快的找到最佳匹配的方法。
Method
- 输入两张分别由相机和拍到的图片和,目标是恢复一组像素的对应关系,其中
- 文章的主题框架如下图所示:
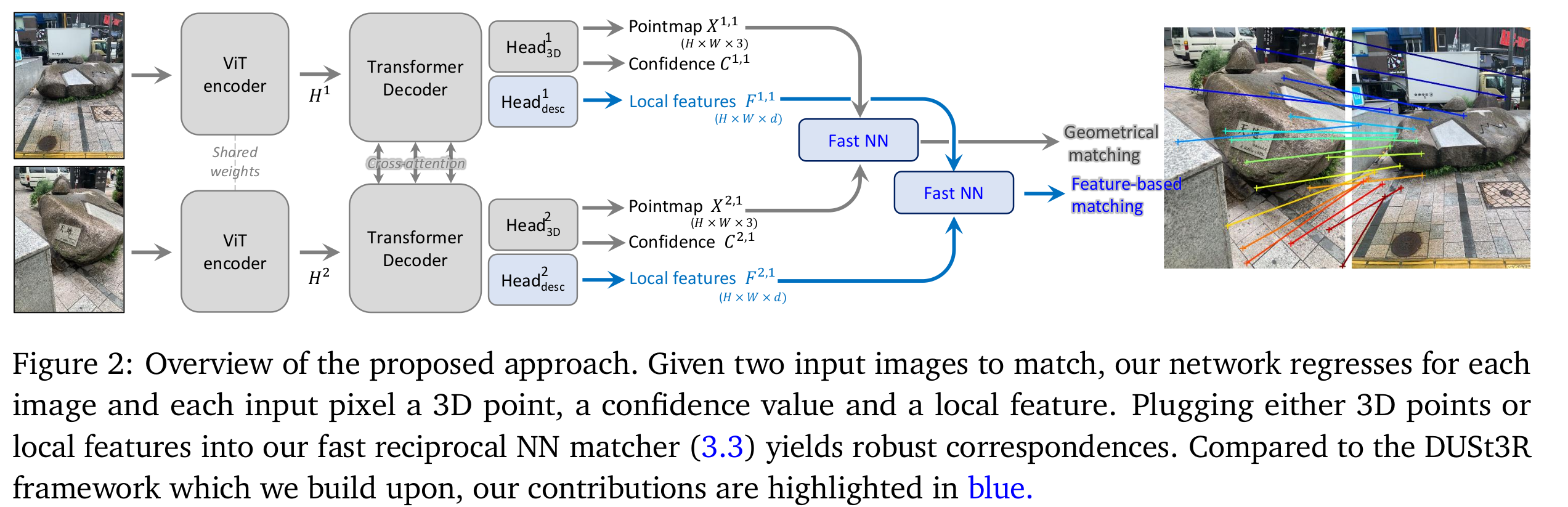
The DUSt3R framework
- 介绍了DUSt3R的框架,这里不再赘述。可以参考之前的博客文档:DUSt3R阅读笔记
Matching prediction head and loss
-
Matching head
- 使用一个2层的MLP作为匹配的head,并使用GELU作为激活函数,最终再把局部feature做归一化。
-
Matching objective
- 我们希望:每一个图片中的一个描述子,都最多匹配上一个其他图片上的描述子。因此对ground truth的匹配对使用infoNCE损失来计算:
- 其中表示每幅图像考虑的像素子集。这里其实就是交叉熵loss,是像素级的交叉熵loss,只有网络回归到正确的像素上时,才会有比较小的loss。
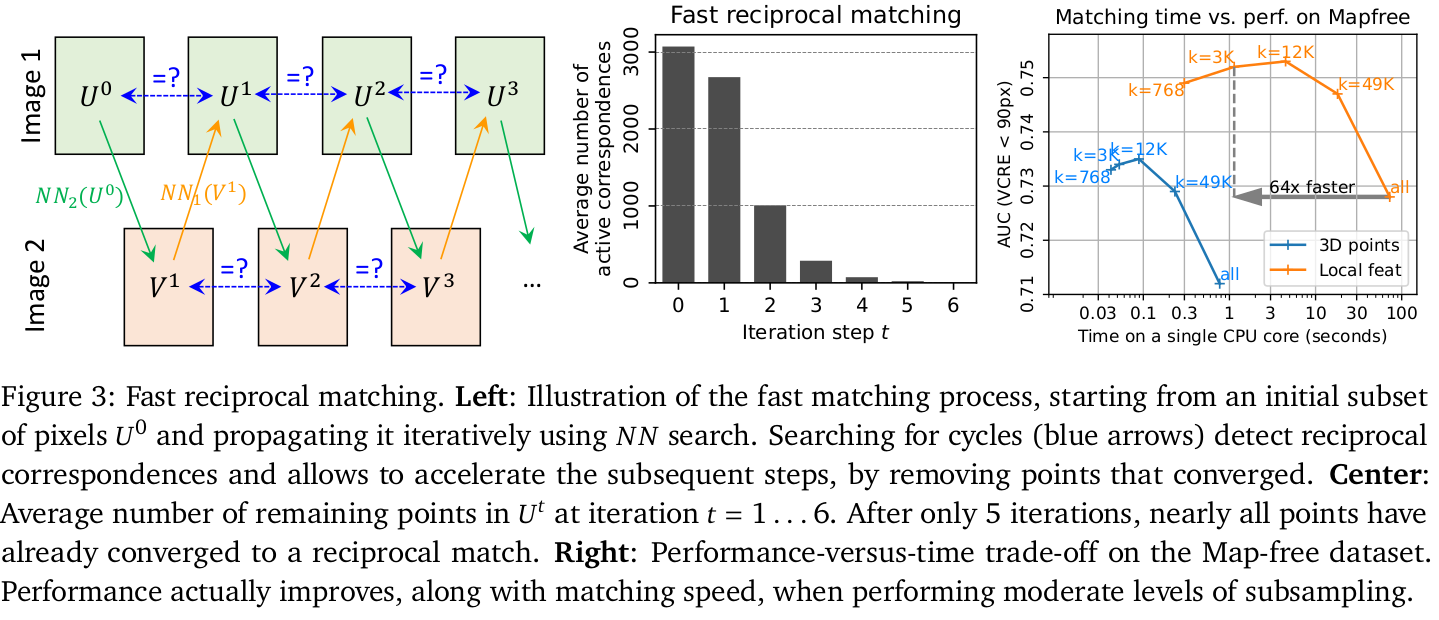
Fast reciprocal matching 快速的互匹配
- 给定一组预测后的特征图,我们如何从中找到特征的匹配对呢?比如要找最近邻的匹配对:
- 在这种高维数据中,K-d tree也会变得速度很慢。
- 作者提出了一种基于sub-sampling(子采样)的快速匹配方法。从初始的稀疏的k个像素集合开始迭代(通常是在上均匀采样)。每个像素都映射到的NN像素上,记作,然后再把中的像素映射回上的最近像素上:
- 此时和中相同的像素,以及其在中的对应像素,就被认为是匹配对。然后把这些点在下一次迭代中去掉。并映射得到,此时找到和之间相同的像素,得到这一组迭代的匹配对。
Coarse-to-fine matching
- 受限于ViT的参数限制,MASt3R只能处理最大512像素的输入,因此对于高分辨率的图片,需要先缩小尺寸进行匹配,然后根据对应关系放大回原始分辨率。这可能会导致性能下降,甚至导致定位精度和重建精度都下降。
- 程序首先在两幅缩小版本的图片上进行匹配,把这组通过sub-sampling k得到的粗匹配对记为。
- 然后在在两张原始图像上分别生成窗口和,每个窗口最大包含512个像素,并且每个图像上相邻窗口有50%的重叠度。
- 枚举所有可能的窗口组合,,从中选择一个覆盖大多数粗匹配对的几何。
- 具体做法:以贪婪的方式逐个添加窗口对,直到覆盖了90%的粗匹配对。
- 最后每个窗口对独立进行匹配,并所有窗口的匹配集合起来,得到最终全图的匹配对。
Experiment
- 作者用了14个数据集来训练,包括Habitat,ARKitScenes,Blended MVS,MegaDepth,Static Scenes 3D,ScanNet++,CO3D-v2,Waymo,Mapfree,WildRgb,VirtualKitti,Unreal4K,TartanAir和一个内部的数据集,包含了室内、室外、合成、真实世界、以物体为中心等数据。
- 用DUSt3R的权重初始化MASt3R。并且每个epoch随机选择65万个样本进行训练,共训练了35个epoch,学习率设置为0.0001。
- 训练时,每个图片初始化4096个对应像素,如果一组图片中找不到这么多像素对,就随机用错误的对应关系来填充。
- 最后,找到24维向量之间的最近邻关系,用K-d tree会非常慢,因此使用的是一个加速的库FAISS

实测数据

MASt3R阅读笔记(DUSt3R的改进模型)
https://fansaorz.github.io/2025/01/12/MASt3R-阅读笔记/