DUSt3R阅读笔记(COLMAP的端到端版本)
相关文档
- 项目链接:https://europe.naverlabs.com/research/publications/dust3r-geometric-3d-vision-made-easy/
- 代码链接:https://github.com/naver/dust3r
- 论文链接:https://arxiv.org/pdf/2312.14132
Introduction
- 现代的SfM和MVS方法主要在解决一系列的最小化问题:特征匹配,寻找基本矩阵,三角化特征点,稀疏重建,估计相机位姿以及稠密重建(也就是colmap整个流程)。
- 然而每个步骤都不能完美的解决,并且为下一个步骤添加噪声。(这不就是自动驾驶的pipeline?这样看来DUSt3R的方法和目前的自驾里的端到端有点异曲同工之妙),同时作者认为传统的方法中,每个模块并不能互相帮助,是一个单向传播的过程(不能像learning一样实现反向传播),即稠密重建不能帮助优化相机位姿进而优化稀疏重建。
- 并且SfM在相机共视区域较小时会失败
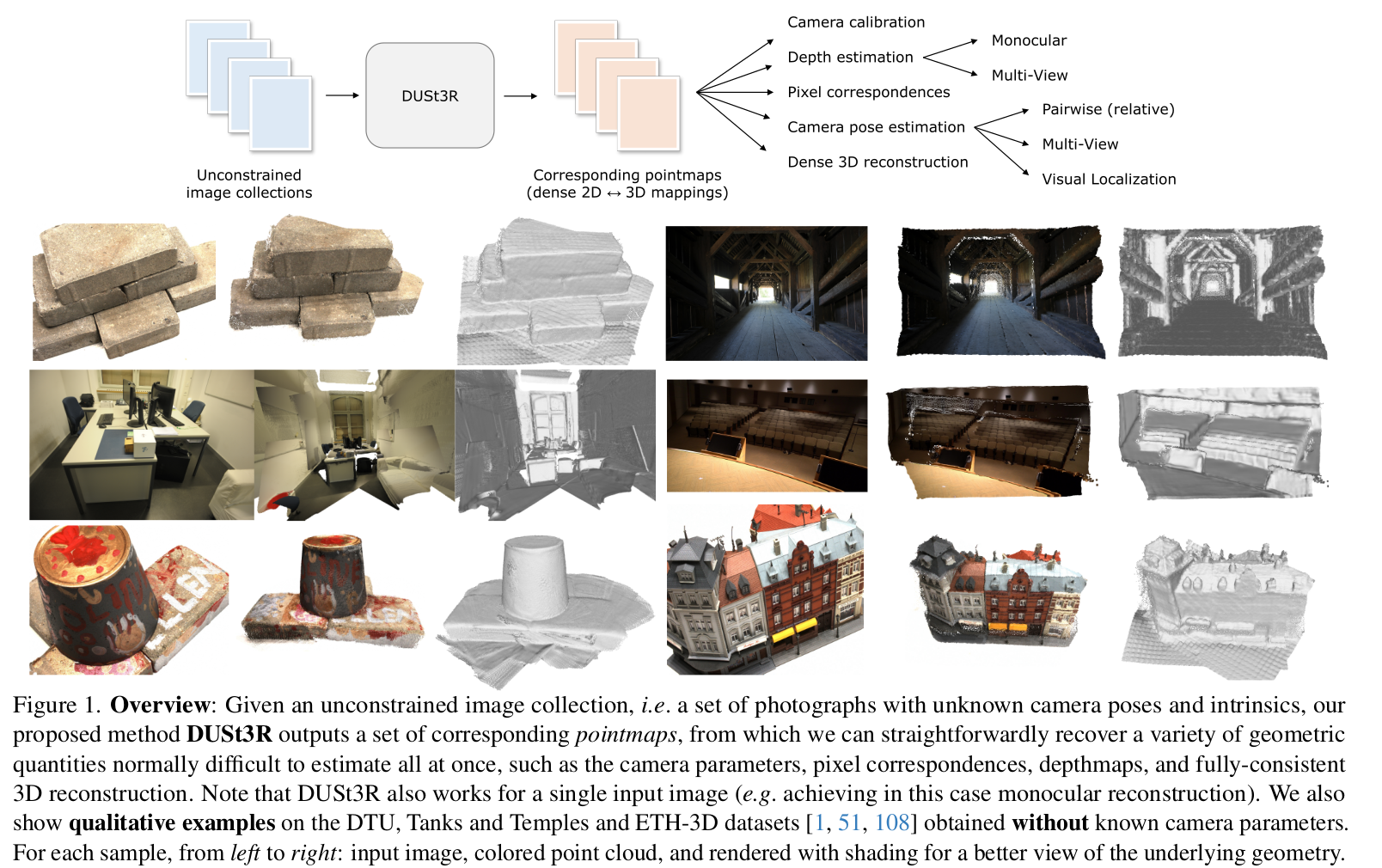
- 作者使用了一个Transformer架构的模型,通过输入一组图像对,直接输出:
- 场景的几何信息
- 图像的像素点和场景的几何点的对应关系
- 图像对的相对位姿
- 通过大量的训练数据,以全监督的方法训练模型,从而实现端到端的重建
- 以上只是针对输入两张图像的重建,当输入多张图像时,作者针对每一组图像对的点图做了全局的BA。在SfM中,BA是通过计算重投影误差实现的,而在DUSt3R中,作者根据空间中的点的对齐情况,直接优化相机位姿。
- 总结,文章的主要贡献是:
- 提出了第一个端到端的3D重建流程
- 提出点图(pointmap)的概念,使得网络可以直接预测场景的几何信息,而不需要各种相机的参数
- 引入了一个优化程序,实现多视图的全局对齐
Method
- Pointmap介绍
- Pointmap记作,代表一个尺寸为的RGB图像的每个像素点,和三维空间中的点的一一映射关系。假设每一个像素点都和空间中的一个点有对应关系,忽略半透明的情况
网络结构
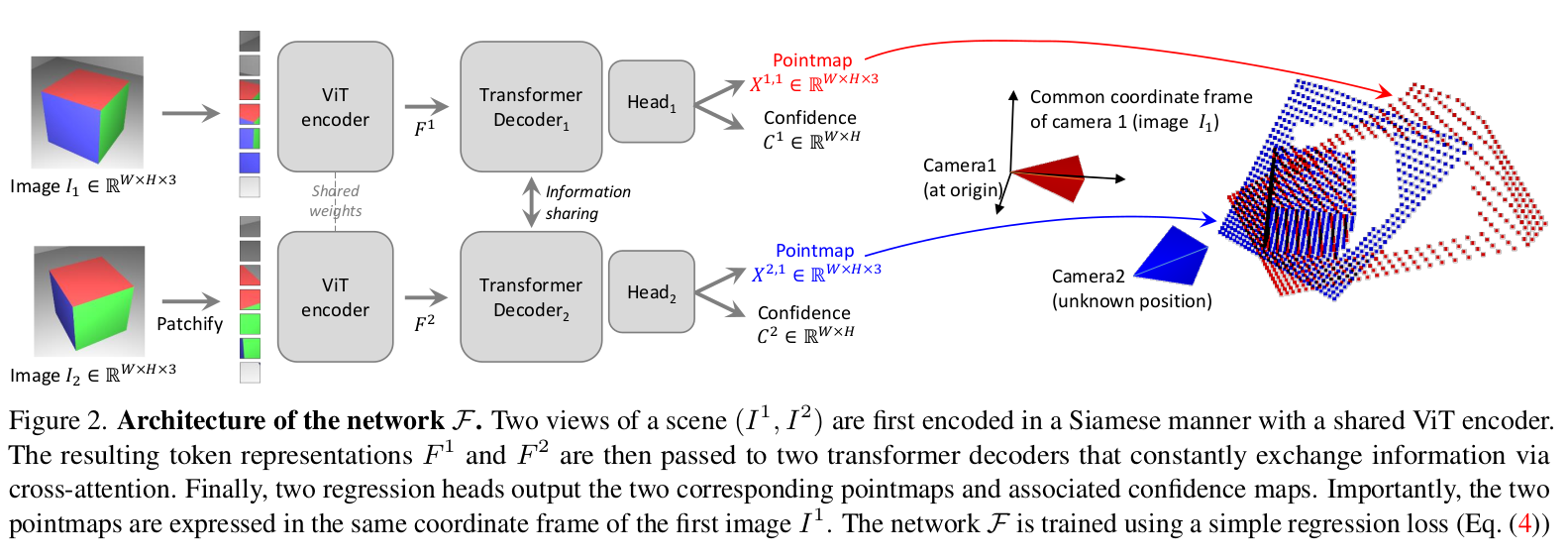
- 网络由两个独立的分支组成,每个分支接收一个图像,每个分支都包含一个Encoder,一个Decoder和一个回归head。
- 两个输入图像首先经过共享权重的ViT Encoder,得到
- Decoder首先做self-attention,单个视图的token互相关注,然后做cross-attention,两个视图的token互相关注。这里的cross-attention可以在两个分支之间共享信息,这样可以实现对齐的pointmap
Loss设计
3D点的欧式距离Loss
- 根据GroundTruth中的点,得到两个图片的pointmap,以及两个图片对应的有效像素集。在这个像素集合中,每一个像素点根据两个pointmap计算出来的两个3D点,计算3D点之间的欧氏距离,作为loss。
- 同时由于尺度问题,需要添加一个缩放因子,将预测点和真实点进行归一化, 表示为有笑点到原点的平均距离
置信度Loss
- 作者这里假设了每个像素只对应一个3D点,但实际情况并非如此,对于天空或者玻璃就不适用,因此额外添加了一个置信度参数。这里的loss主要是和所有有效像素的欧式距离的Loss有关:
效果

后续改进论文
DUSt3R阅读笔记(COLMAP的端到端版本)
https://fansaorz.github.io/2025/01/05/DUSt3R阅读笔记/