Loss函数
L1 Loss
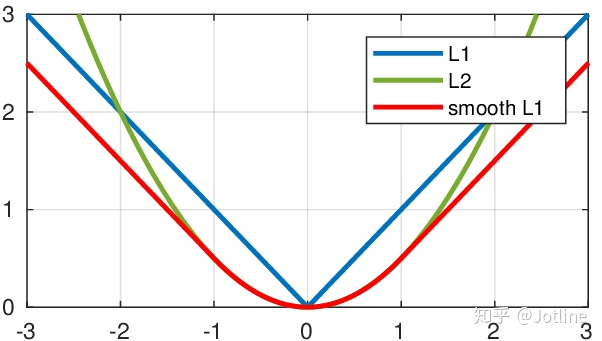
- L1 Loss,即绝对值误差。
- 公式:
- L1 loss在零点不平滑,用的较少。在回归和简单的模型中使用
L2 Loss
- L2 Loss,即均方误差。
- 公式:
- 在回归任务;数值特征不大;问题维度不高时使用
Smooth L1 Loss
-
Smooth L1 Loss,即平滑L1损失。
-
公式:
-
平滑版的L1 Loss。仔细观察可以看到,当预测值和ground truth差别较小的时候(绝对值差小于1),其实使用的是L2 Loss;而当差别大的时候,是L1 Loss的平移。Smoooth L1 Loss其实是L2 Loss和L1 Loss的结合,它同时拥有L2 Loss和L1 Loss的部分优点。
-
当预测值和ground truth差别较小的时候(绝对值差小于1),梯度不至于太大。(损失函数相较L1 Loss比较圆滑)
-
当差别大的时候,梯度值足够小(较稳定,不容易梯度爆炸)。
SSIM Loss
- Structural Similarity (SSIM),即结构相似性。是用来衡量两张图片的质量的一种指标。
- 结构相似度指数从图像组成的角度将结构信息定义为独立于亮度、对比度的反映场景中物体结构的属性,并将失真建模为亮度、对比度和结构三个不同因素的组合。
- 用均值作为亮度的估计,标准差作为对比度的估计,协方差作为结构相似程度的度量。
- 公式:
- Pytorch 计算 SSIM Loss 的代码:
1 | |
PSNR(峰值信噪比)公式和作用
- PSNR 是一种评价图像质量的指标,用于衡量原始图像和重建图像之间的差异。
- 定义为:给定一个原始图像,另一个图像为重建图像,PSNR 就是原始图像和重建图像之间的均方误差 MSE 的平均值。
- 计算公式为:
- 其中,MSE 是原始图像和重建图像之间的均方误差,MAX 是图像颜色的最大数值,8 位采样点表示为 255。
交叉熵 loss
- 交叉熵是信息论中的概念,用来衡量一个概率分布和另一个概率分布之间的距离。
- 在分类问题中,我们通常有一个真实的概率分布(训练数据的分布),以及一个模型生成的概率分布,交叉熵 keyi 衡量这两个分布之间的距离。
- 在模型训练时,通过最小化交叉熵损失函数,可以使模型预测的概率分布逐步接近真实的概率分布。
- 公式:
交叉熵由来
-
信息量:
-
信息论中,信息量的表示方式:
-
即:概率越小的事件,信息量越大。
-
-
熵:
-
相对熵(KL 散度):
-
如果我们对于同一个随机变量有两个单独的概率分布和,可以用 KL 散度衡量这两个分布之间的距离:
-
n 为事件的所有可能性,D 的值越小,表示 q 分布和 p 分布越接近。
-
-
交叉熵:
-
把上述公式变形:
-
其中, 就是两个分布的交叉熵。
-
-
举例
-
假设N=3,期望输出为p=(1, 0, 0),实际输出为q1 = (0.5, 0.2, 0.3),q2 = (0.8, 0.1, 0.1),那么交叉熵为:
-
q2的交叉熵更小,所以q2 分布更接近期望分布 p。
参考文档
Loss函数
https://fansaorz.github.io/2024/08/17/Loss函数/