Cross-Attention流程介绍
Self-Attention
举例
- 图像中如何使用Self-Attention
- 假设图像分成了4块,每块都有RGB三个通道,将其展开可以得到一个4x3的“矩阵”(每一块图像看做一个元素)
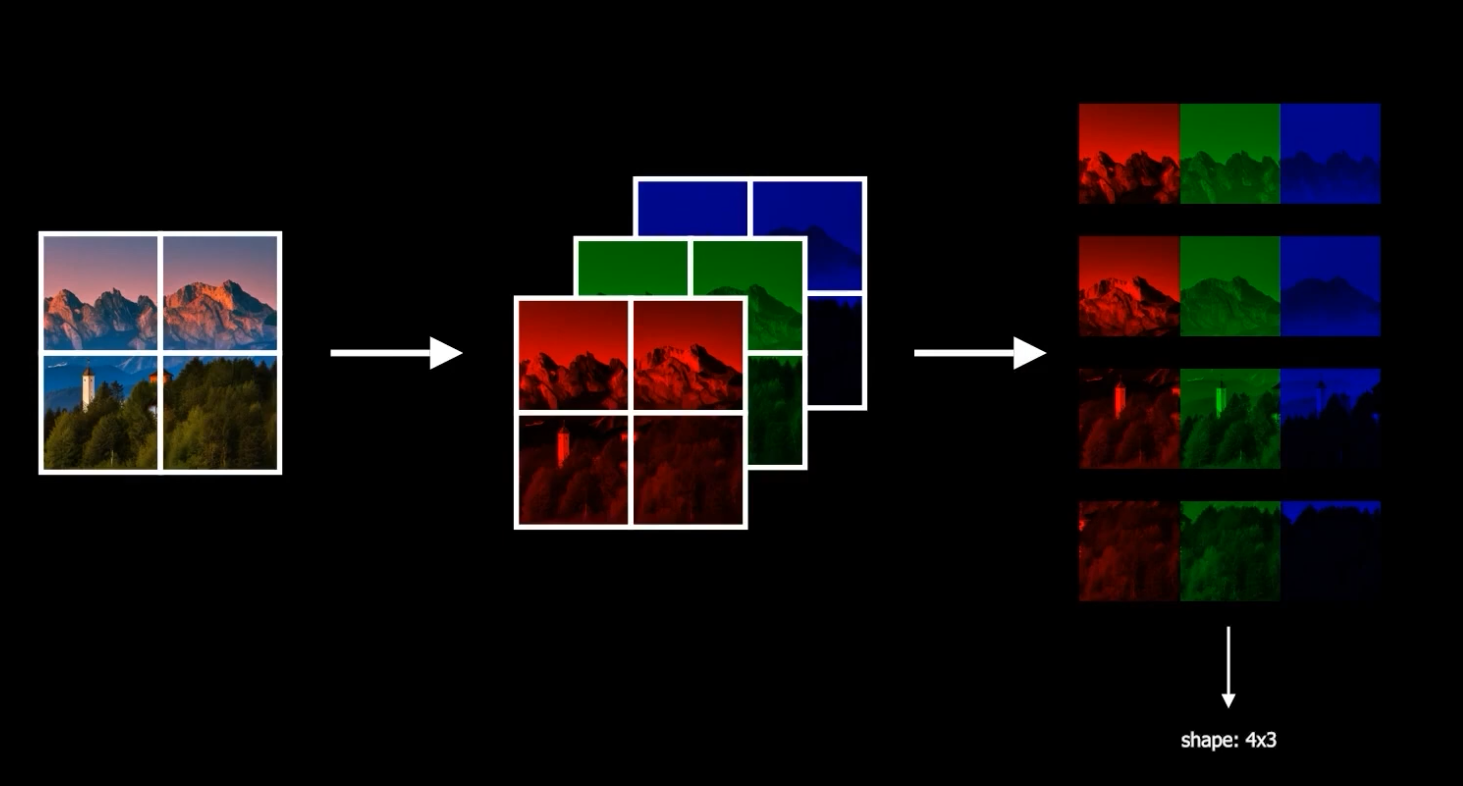
- 现在想根据这个4x3的矩阵计算出对应的QKV,我们首先先随机初始化QKV的权重,并将其与图像矩阵相乘,得到QKV。此时的QKV维度均为:

-
对于上式来说,首先计算。由于Q和K的维度均为,因此计算后维度为,每个数字代表两个矩阵之间的相似程度。因此可以解释为相似性度量。
-
对执行Softmax,并和矩阵V相乘,得到最终的输出。和矩阵V相乘可以理解为注意力机制,即根据Q和K的相似程度对V进行加权。


-
以上就是Self-Attention的计算过程。完全根据自身的像素块,计算互相之间的相似程度,然后根据相似程度对V进行加权。
-
最后要把Self-Attention的结果映射回原始的图像维度,增加一个用于映射。并把映射的结果和原始图像进行相加,得到最终的输出。
- 相加的原因:
- 原始的每个像素也需要对自己给予很大的关注度
- 这样Self-Attention可以控制什么时候跳过self-attention操作
- 相加的原因:
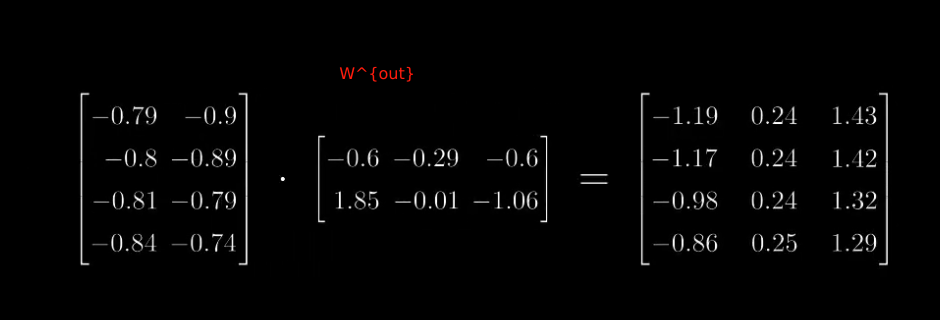

Cross-Attention
-
Cross-Attention和Self-Attention不同,这里只由Q是从原始的图像输入中计算而来,K和V是条件信息的投影。
-
K和V以文字的输入形式举例,

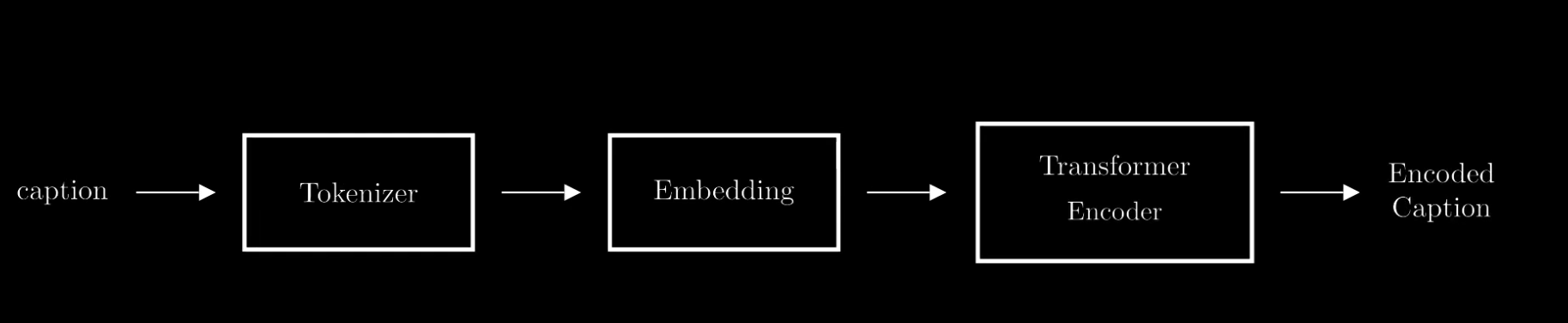
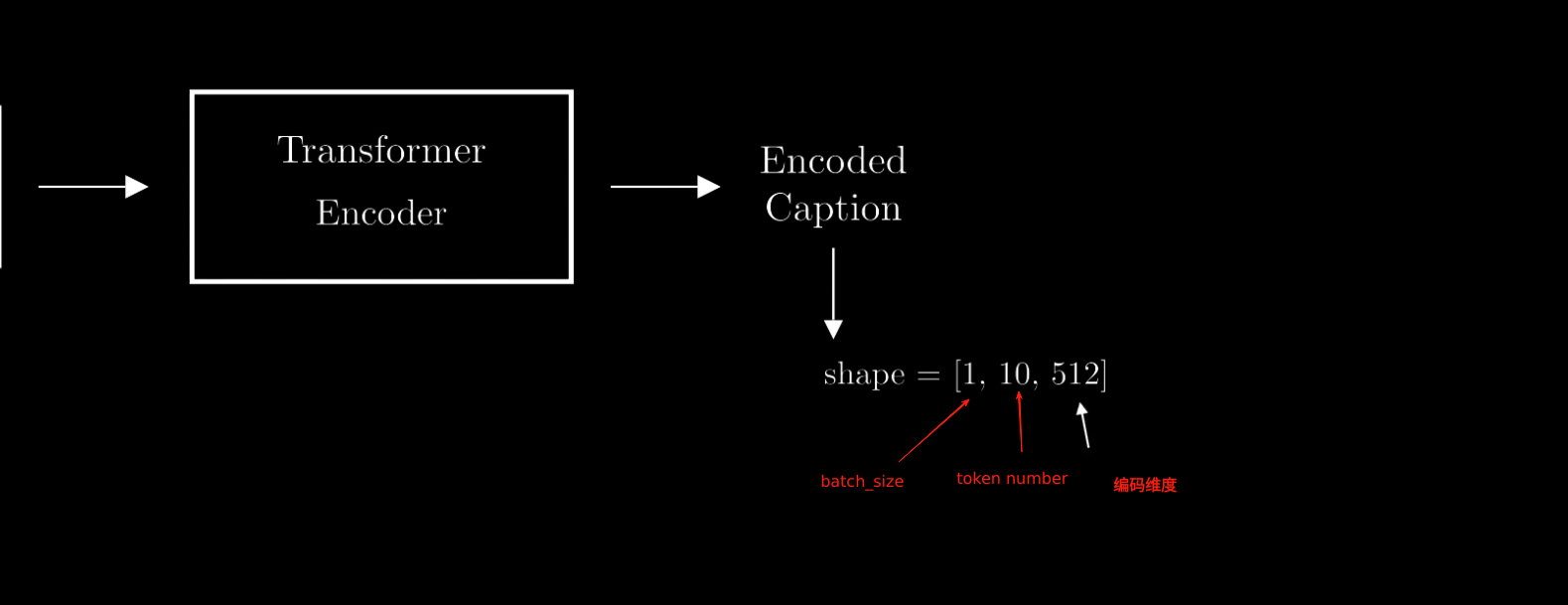
- 例如输入文字内容为“I love mountains”,Encoder之后的输入维度为,Token长度是3,每个token都编码为6维向量,batch size为1

- 此时得到了 和 。 继续执行和Self-Attention一样的操作。首先计算$ Q \cdot K^T $。
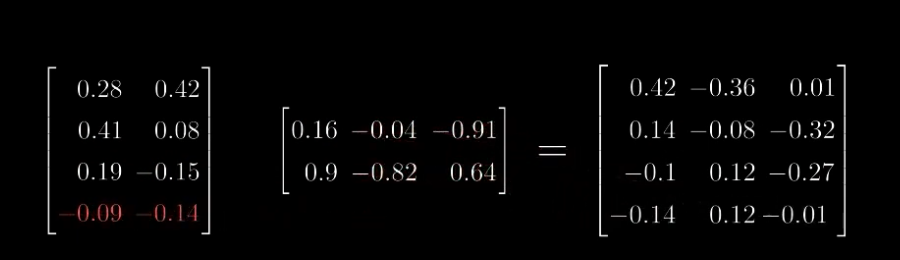
- SoftMax
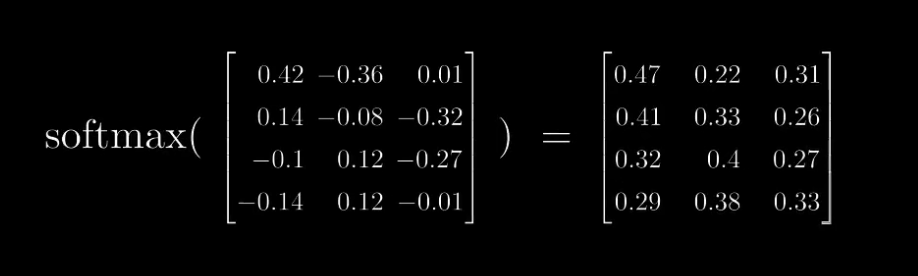
- 最后是和V相乘,这里可以理解为每个像素,对于每个token的关注度,或者参考的权重值是多少。
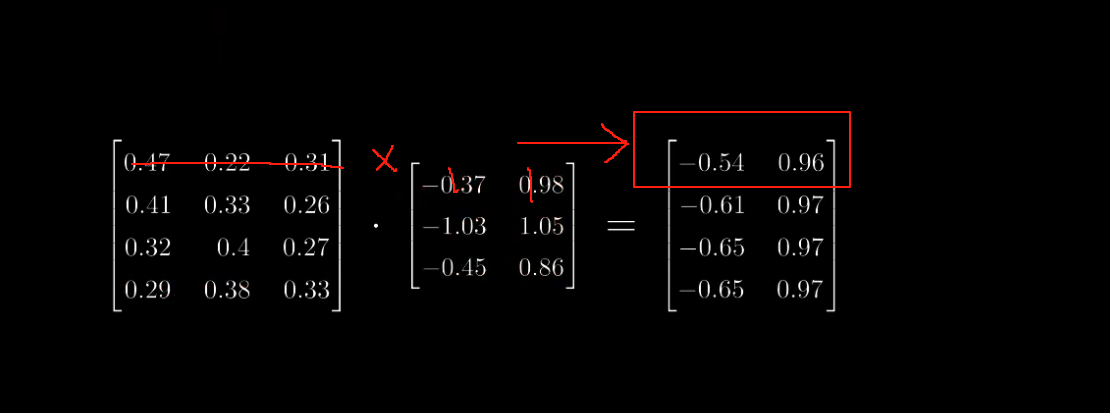
- 使用来把cross-attention的结果映射回原始的图像维度。
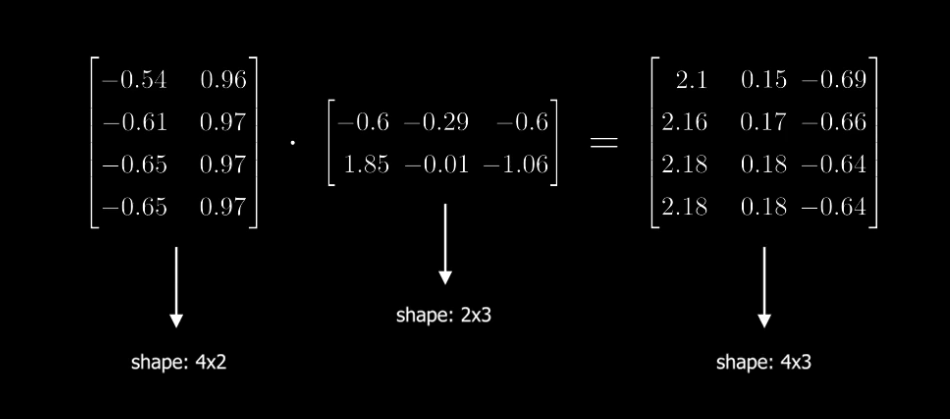
- 再和输入的图像相加,得到最终的输出。
参考文档
Cross-Attention流程介绍
https://fansaorz.github.io/2024/08/11/Cross-Attention/